Lesson 2 - FastAI



Lets create our very own bear classifier using images we grab from online!
from pathlib import Path
root = Path().cwd()/"images"
#rmtree(root) #Deletes all previous images
from jmd_imagescraper.core import *
duckduckgo_search(root, "Grizzly", "Grizzly bears", max_results=100)
duckduckgo_search(root, "Black", "Black bears", max_results=100)
duckduckgo_search(root, "Teddy", "Teddy bears", max_results=100)
from jmd_imagescraper.imagecleaner import *
display_image_cleaner(root)
bears = DataBlock(
blocks=(ImageBlock, CategoryBlock), #Assign independent and dependent blocks
get_items=get_image_files, #Send the images
splitter=RandomSplitter(valid_pct=0.2, seed=42), #Split validation data
get_y=parent_label, #Get labels
item_tfms=Resize(128)) #Resize all images to be same
dls = bears.dataloaders(root) #path goes here (I named it root)
dls.valid.show_batch(max_n=4, nrows=1)

bears = bears.new(item_tfms=Resize(128, ResizeMethod.Squish))
dls = bears.dataloaders(root)
dls.valid.show_batch(max_n=4, nrows=1)

Squishing
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Pad, pad_mode='zeros'))
dls = bears.dataloaders(root)
dls.valid.show_batch(max_n=4, nrows=1)

Padding
bears = bears.new(item_tfms=RandomResizedCrop(128, min_scale=0.3))
dls = bears.dataloaders(root)
dls.train.show_batch(max_n=4, nrows=1, unique=True)

Cropping
bears = bears.new(item_tfms=Resize(128), batch_tfms=aug_transforms(mult=2))
dls = bears.dataloaders(root)
dls.train.show_batch(max_n=8, nrows=2, unique=True)

bears = bears.new(
item_tfms=RandomResizedCrop(224, min_scale=0.5),
batch_tfms=aug_transforms())
dls = bears.dataloaders(root)
learn = cnn_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(4)
Seems like our model did pretty good!
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()

interp.plot_top_losses(5, nrows=1)

Notice that the last image isn't even a bear -- We should remove that!
cleaner = ImageClassifierCleaner(learn)
cleaner
learn.export()
path = Path()
path.ls(file_exts='.pkl')
learn_inf = load_learner(path/'export.pkl')
uploader = widgets.FileUpload()
uploader
img = PILImage.create(uploader.data[0])
img.to_thumb(192)

learn_inf.dls.vocab
learn_inf.predict(img)
It's correct, nice!
uploader = widgets.FileUpload()
uploader
img = PILImage.create(uploader.data[0])
img.to_thumb(192)

learn_inf.predict(img)
Haha its between black bear and teddy bear - thats intresting
btn_upload = widgets.FileUpload()
btn_upload
img = PILImage.create(btn_upload.data[-1])
out_pl = widgets.Output()
out_pl.clear_output()
with out_pl: display(img.to_thumb(128,128))
out_pl
pred,pred_idx,probs = learn_inf.predict(img)
lbl_pred = widgets.Label()
lbl_pred.value = f'Prediction: {pred}; Probability: {probs[pred_idx]:.04f}'
lbl_pred
btn_run = widgets.Button(description='Classify')
btn_run
def on_click_classify(change):
img = PILImage.create(btn_upload.data[-1])
out_pl.clear_output()
with out_pl: display(img.to_thumb(128,128))
pred,pred_idx,probs = learn_inf.predict(img)
lbl_pred.value = f'Prediction: {pred}; Probability: {probs[pred_idx]:.04f}'
btn_run.on_click(on_click_classify)
VBox([widgets.Label('Select your bear!'),
btn_upload, btn_run, out_pl, lbl_pred])
#%watermark -v -m -p pandas,numpy,watermark,fastbook,voila,fastai
- Provide an example of where the bear classification model might work poorly in production, due to structural or style differences in the training data.
Since most of the images are of bears caught in good light and close to the camera, it would work poorly if subjected to blurry, far away, poor lighting photos of bears. - Where do text models currently have a major deficiency?
They can generate context-appropriate text, but struggle generating correct responses. For example, taking knowledge of medical information to generate medically correct responses. - What are possible negative societal implications of text generation models?
Because it can generate compelling responses based on the context, it could cause people to assume it is correct, when infact it is not. So, simply put, distribution of misinformation on a potentially large scale. - In situations where a model might make mistakes, and those mistakes could be harmful, what is a good alternative to automating a process?
Having a human overseer. - What kind of tabular data is deep learning particularly good at?
High cardinality (a lot of unique value) categorical columns, such as zip code or product ID. - What's a key downside of directly using a deep learning model for recommendation systems?
The recommendation system is actually not very helpful and bias. For example, if you like the book Legend by Marie Lu (great book btw), it will suggest other books by the same author like Prodigy and Champion. Well, these are part of the same series so this is actually not very helpful. - What are the steps of the Drivetrain Approach?
Define objective, Levers (Hyperparameters), Data collection, and Models - How do the steps of the Drivetrain Approach map to a recommendation system?
Objective is to drive the sales.
Levers is the ranking of the recommendations.
Data is collected to generate recommendations that will cause new sales. - Create an image recognition model using data you curate, and deploy it on the web.
- What is
DataLoaders?
A fastai class that stores multiple DataLoader objects you pass to it, and makes them available as train and valid. - What four things do we need to tell fastai to create
DataLoaders?
Type of data
How to get data
How to get Labels
How to create validation set - What does the
splitterparameter toDataBlockdo?
Splits data into subsets of train and validation set. - How do we ensure a random split always gives the same validation set?
Define a seed. - What letters are often used to signify the independent and dependent variables?
x is the independent, while y is the dependent. - What's the difference between the crop, pad, and squish resize approaches? When might you choose one over the others?
Crop cuts part of the image to the assigned size.
Pad adds 0 pixels to the sides of the image.
Squish either squishes or stretches the image.</br>
Choosing the right one depends on the data and problem. - What is data augmentation? Why is it needed?
Data augmentation creates variation of the input data. This makes the model more robust (generalizable) and creates a larger dataset if the dataset is small. - What is the difference between
item_tfmsandbatch_tfms?
item_tfms are transformations applied to a single data sample.
batch_tfms are applied to batched data samples. - What is a confusion matrix?
A representation of the predictions vs the labels. Looks like an identity matrix. - What does
exportsave?
The model we trained. - What is it called when we use a model for getting predictions, instead of training?
Inference - What are IPython widgets?
IPython widgets is a mix of JavaScript and Python functionalities that let us build and interact with GUI components within Jupyter notebooks. For example, the uploader button seen above. - When might you want to use CPU for deployment? When might GPU be better?
CPU is good/cost effective when analyzing single pieces of data at a time. GPUs are best for doing work in parallel or in batches at a time. - What are the downsides of deploying your app to a server, instead of to a client (or edge) device such as a phone or PC?
Network connection could cause latency problems. - What are three examples of problems that could occur when rolling out a bear warning system in practice?
Blurry/low resolution images
Bears at night (Night images)
Bears are obstructed by trees - What is "out-of-domain data"?
Data that was not present within models training input. - What is "domain shift"?
Type of data changes gradually over time. - What are the three steps in the deployment process?
https://raw.githubusercontent.com/fastai/fastbook/780b76bef3127ce5b64f8230fce60e915a7e0735/images/att_00061.png
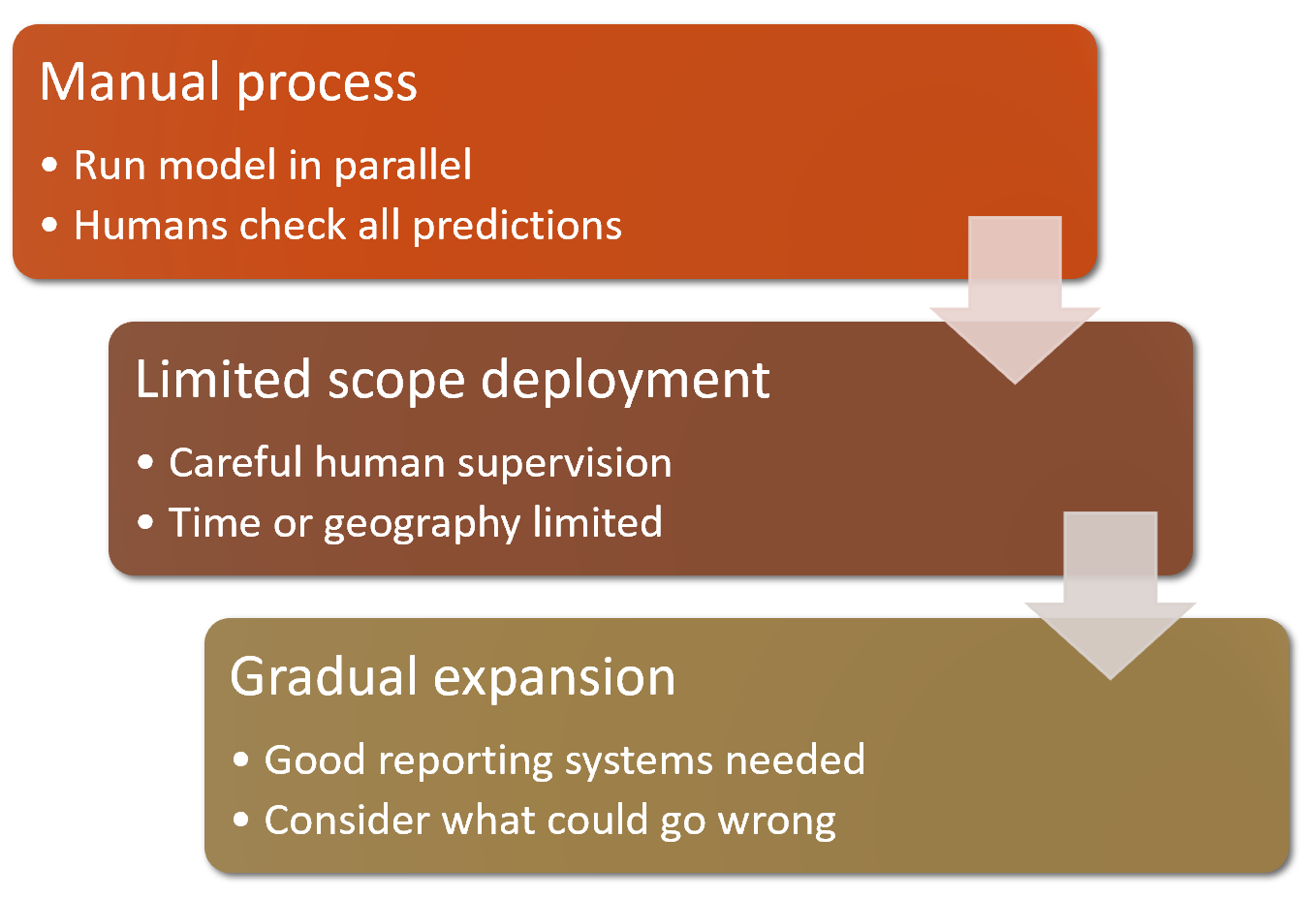{kind=link}
- Consider how the Drivetrain Approach maps to a project or problem you're interested in.
- When might it be best to avoid certain types of data augmentation?
For example, if the features in the images take up the whole image, then cropping may result in loss of information: Here, squishing or padding may be more useful. - For a project you're interested in applying deep learning to, consider the thought experiment "What would happen if it went really, really well?"
- Start a blog, and write your first blog post. For instance, write about what you think deep learning might be useful for in a domain you're interested in.
https://usama280.github.io/PasteBlogs/